We will write a CUDA program to multiply two vectors, each having 10000 elements. Print the result.
- Print the execution time for GPU.
- Run the same code for CPU and print the execution time.
- Compare both execution time and explanation.
Sequential Implementation for this is very easy one -
for (int i=0 ; i<size ; i++)
{
C[i] = A[i] * B[i];
}
As the parallel implementation -
We are going to launch a 1D Grid as the same size as the number of elements in the vector. And each thread is going to multiply two elements one from each vectors together and store the results back to the output vector.
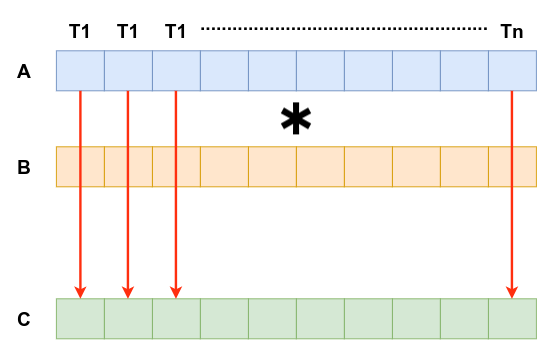
Steps in CUDA Program -
Code Explanation - Code
Please Refer the code above Code link ↑ , Below I have discussed the snippets in detail -
-
Let’s name our kernel
mul_vec_gpu__global__ void mul_vec_gpu(int * a, int * b, int* c, int size) { int index = blockDim.x * blockIdx.x + threadIdx.x; if (index < size) c[index] = a[index] * b[index]; }This kernel takes 4 arguments - Pointer to the input vector A and B , Pointer to the output vector C and size of a vector.
Then we calculated global index. Here we are going to have 1D grid with multiple thread blocks so we can calculate global index by summing up block offset for 1D thread block and
threadIdx.xvalues.Then we are going to check using a
if conditionwhether our global index is within the size of our vector.Then all we have to multiply the elements with global index in both A and B vectors and store the result to vector C.
That’s it for our kernel implementation.
-
Now let’s move on to the main function.
Here we are going to multiply two, 10000 elements vectors. First we set the vector size.
Then we launched 1D Grid here with the block size 128.
int main() { int size = 10000; int block_size = 128;Now we can calculate the number of bytes we need to hold each vector by multiplying size variable by the number of bytes per integer.
//number of bytes needed to hold element count size_t NO_BYTES = size * sizeof(int);Now, we need host pointer to A and B vectors also we are going to transfer the results from device back to the host as well, So we need a host pointer to hold results of GPU calculation
*gpu_result.// host pointers int *h_a, *h_b, *gpu_result;Now we need to allocate memory for each of these pointers, we can do this using
malloc()function.//allocate memory for host size pointers h_a = (int *)malloc(NO_BYTES); h_b = (int *)malloc(NO_BYTES); gpu_result = (int *)malloc(NO_BYTES);Then we are going to randomly initialize A and B vectors.
- For that I used
rand()andsrand()functions and limit the generated random value to value between 0 - 255 by performing bit-wise& operation.
//initialize h_a and h_b vectors randomly time_t t; srand((unsigned)time(&t)); for (size_t i = 0; i < size; i++) { h_a[i] = (int)(rand() & 0xFF); } for (size_t i = 0; i < size; i++) { h_b[i] = (int)(rand() & 0xFF); }Then we have to declare the corresponding device pointer as well, we can allocate memory for each of those pointers using
cudaMalloc()function.int *d_a, *d_b, *d_c; cudaMalloc((int **)&d_a, NO_BYTES); cudaMalloc((int **)&d_b, NO_BYTES); cudaMalloc((int **)&d_c, NO_BYTES);Here we are transferring memory for A and B device pointers from the host.
BUT C vector will be populated by multiplication operation by kernel, so we have to only transfer A and B vectors to device.
We performed memory transfer operation using
cudaMemcpy()function. Make sure that you have set the direction of these function calls tohosttodevice.cudaMemcpy(d_a, h_a, NO_BYTES, cudaMemcpyHostToDevice); cudaMemcpy(d_b, h_b, NO_BYTES, cudaMemcpyHostToDevice); - For that I used
-
Now we set Block and Grid Variable, so here our block variable size is 128 in X dimension which we have already assigned to block_size variable.
-
We can calculate grid size variable by dividing number of elements in the vector by block dimension in X dimension.
But if we look at our vector size and block size variables, here we are going to have 10000 threads, which is not fully divided by the block size value 128. In this type of scenarios, we usually add 1 grid size. This 1 will guarantees that we are going to have more threads than vector size.
//kernel launch parameters dim3 block(block_size); dim3 grid((size / block.x) + 1);Then we can launch our kernel with these kernel parameters and input arguments.
We have to wait until our kernel execution finished here, so we need to add
cudaDeviceSynchronize()function to block the host execution until kernel execution finish.sum_arrays_gpu <<< grid, block >>> (d_a, d_b, d_c, size); cudaDeviceSynchronize();After the execution finish, results of the kernel multiplication is in C vector in the device. So we have to transfer memory back to the host.
For that again we are going to use
cudaMemcpy()function. Here destination pointer will begpu_resultin the host source pointer is C device pointerd_cand we have to specify memory copy direction as device to host.cudaMemcpy(gpu_result, d_c, NO_BYTES, cudaMemcpyDeviceToHost);Then we can reclaim the memory for pointers in host and device.
cudaFree(d_c); cudaFree(d_b); cudaFree(d_a); free(gpu_result); free(h_a); free(h_b);This was the implementation of parallel multiplication in GPU.
CPU Implementation
For that we added another function below the kernel code to multiply vectors in CPU mul_vec_cpu().
void mul_vec_cpu(int * a, int * b, int * c, int size)
{
for (int i = 0; i < size; i++)
{
c[i] = a[i] * b[i];
}
}
This function takes pointers to three integers vectors and size of the vectors as an argument.
So now we need to call this function from main() function. So for that added another pointer to hold C vector and then we need to allocate memory for that host pointer as well.
// host pointers
int *h_a, *h_b, *gpu_result, *cpu_result;
allocating memory for this *cpu_result host pointer.
//allocate memory for host size pointers
h_a = (int *)malloc(NO_BYTES);
h_b = (int *)malloc(NO_BYTES);
gpu_result = (int *)malloc(NO_BYTES);
cpu_result = (int *)malloc(NO_BYTES);
After initializing vector A and B we can perform vector multiplication in CPU.
mul_vec_cpu(h_a, h_b, cpu_result, size);
Comparing the CPU and GPU result
Before freeing the memory we add this validity check whether the multiplication result in CPU and GPU is same or not.
//compare_vectors
printf("After Multiplication Validity Chaeck : \n");
for (int i = 0; i < size; i++)
{
if (gpu_result[i] != cpu_result[i])
{
printf("Resultant Vectors are different \n");
return;
}below the kernel code
}
printf("Resultant vectors of CPU and GPU are same \n");
Execution Time Calculation
In CUDA program, we usually wants to compare the performance between GPU implementation with CPU implementation and also in case of we have multiple solutions to solve same problem then we want to find out the best performing or fastest solution as well.
-
We will note the CPU clock cycle before and after the operation (function calls), then the difference between those two will give us the elapsed clock cycles between the operations.
Then we can divide that value by clock cycles per second value and get the number of seconds elapsed during the operation.
Most of our program will have execution time in millisecond or micro second range
-
**CPU Implementation Execution Time : **
//multiplication in CPU clock_t cpu_start, cpu_end; cpu_start = clock(); mul_vec_cpu(h_a, h_b, cpu_result, size); cpu_end = clock();Printout the execution time :
printf("CPU mul time : %4.6f \n", (double)((double)(cpu_end - cpu_start) / CLOCKS_PER_SEC));Clocks per cycle is very large value, basically it’s clock speed of our processor that’s why we cast our recorded clock cycles and values after division to
doublevalues otherwise it will show you zeros. -
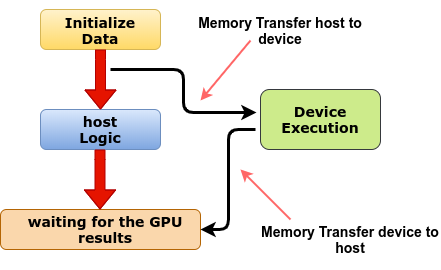
GPU Implementation Execution Time :
GPU execution time - Total execution time including memory transferring times.
I printed here data transfer time to both the directions and kernel execution time separately and finally we can add up those values to get total execution time for GPU implementation.
Clock cycle before and after memory transfer from host to device -
clock_t mem_htod_start, mem_htod_end; mem_htod_start = clock(); cudaMemcpy(d_a, h_a, NO_BYTES, cudaMemcpyHostToDevice); cudaMemcpy(d_b, h_b, NO_BYTES, cudaMemcpyHostToDevice); mem_htod_end = clock();Kernel execution time -
//execution time measuring in GPU clock_t gpu_start, gpu_end; gpu_start = clock(); mul_vec_gpu << <grid, block >> > (d_a, d_b, d_c, size); cudaDeviceSynchronize(); gpu_end = clock();Clock cycle before and after memory transfer from device to host -
clock_t mem_dtoh_start, mem_dtoh_end; mem_dtoh_start = clock(); cudaMemcpy(gpu_result, d_c, NO_BYTES, cudaMemcpyDeviceToHost); mem_dtoh_end = clock();Printing all these three operation -
printf("GPU kernel execution time multiplication time : %4.6f \n", (double)((double)(gpu_end - gpu_start) / CLOCKS_PER_SEC)); printf("Mem transfer host to device : %4.6f \n", (double)((double)(mem_htod_end - mem_htod_start) / CLOCKS_PER_SEC)); printf("Mem transfer device to host : %4.6f \n", (double)((double)(mem_dtoh_end - mem_dtoh_start) / CLOCKS_PER_SEC)); printf("Total GPU time : %4.6f \n", (double)((double)((mem_htod_end - mem_htod_start) + (gpu_end - gpu_start) + (mem_dtoh_end - mem_dtoh_start)) / CLOCKS_PER_SEC));
Result Comparison
CPU implementation execution time is less than the total GPU execution time but if we look the kernel execution time, it is lower than the CPU execution time.
Most of the time in GPU implementation is consumed by the memory transferring operations between host and device. This shows how much of memory overload happen in a program.
Since it was very straightforward calculation, so modern day optimized CPUs are able to perform these calculations very fast. When things are bit more complicated than this, then GPU implementations are easily outperformed the CPU counter parts.
This is because the execution time of the GPU version is dominated by the overhead of copying data between the CPU and GPU memories. This is an important lesson for CUDA developers: it only makes sense to execute something on the GPU when there is a significant amount of computation being performed on each data element.
CPU Execution time for this 10000 size vector multiplication: 0.000030 sec.
As we increase the size of vector we will see the difference, Now Overall GPU execution time is faster.
Vectors are same
size of vectors : 10000000
CPU mul time : 0.031849
GPU kernel execution time mul time : 0.000873
Mem transfer host to device : 0.017912
Mem transfer device to host : 0.008116
Total GPU time : 0.026901
Vectors are same
size of vectors : 100000000
CPU mul time : 0.317796
GPU kernel execution time mul time : 0.008146
Mem transfer host to device : 0.174928
Mem transfer device to host : 0.080483
Total GPU time : 0.263557
Here is the basic performance comparison of different block configuration(Trail and Error Method) for GPU execution time :
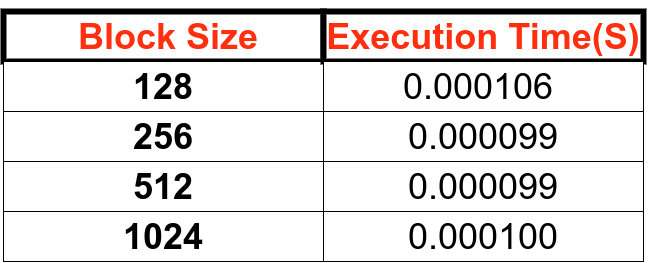
block_size = 128
saurabh@instance-1:~/cuda_test-gcp/mul$ ./vec_mul_128
Validity Check :After Multiplication resultant vectors of CPU and GPU are same
CPU mul time : 0.000030
GPU kernel execution time mul time : 0.000026
Mem transfer host to device : 0.000048
Mem transfer device to host : 0.000028
Total GPU time : 0.000102
block_size = 256
saurabh@instance-1:~/cuda_test-gcp/mul$ ./vec_mul_256
Validity Check :After Multiplication resultant vectors of CPU and GPU are same
CPU mul time : 0.000031
GPU kernel execution time mul time : 0.000026
Mem transfer host to device : 0.000047
Mem transfer device to host : 0.000026
Total GPU time : 0.000099
block_size = 512
saurabh@instance-1:~/cuda_test-gcp/mul$ ./vec_mul_512
Validity Chaeck :After Multiplication resultant vectors of CPU and GPU are same
CPU mul time : 0.000030
GPU kernel execution time mul time : 0.000025
Mem transfer host to device : 0.000048
Mem transfer device to host : 0.000026
Total GPU time : 0.000099
block_size = 1024
saurabh@instance-1:~/cuda_test-gcp/mul$ ./vec_mul_1024
Validity Check :After Multiplication resultant vectors of CPU and GPU are same
CPU mul time : 0.000030
GPU kernel execution time mul time : 0.000027
Mem transfer host to device : 0.000047
Mem transfer device to host : 0.000026
Total GPU time : 0.000100
We can also use the command line visual profiler nvprof.
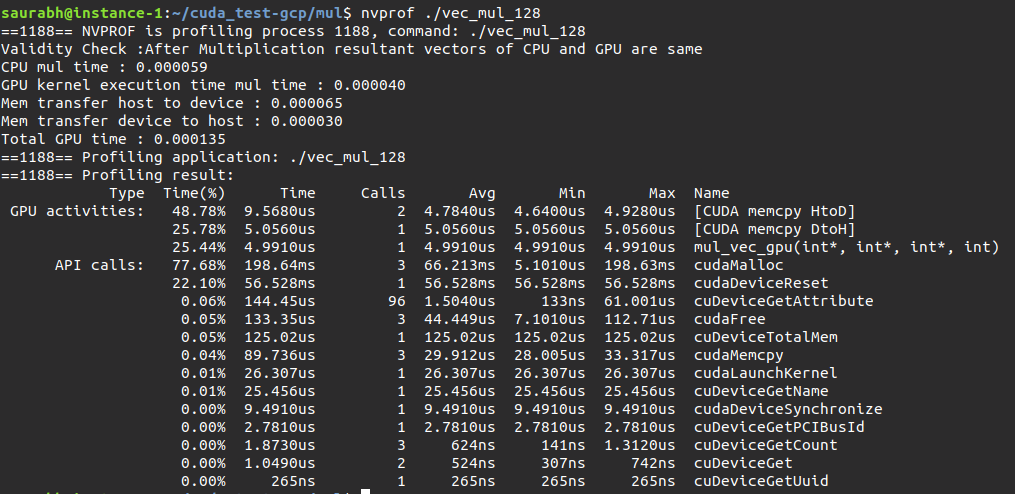
Performance of CUDA Application
In industrial level applications execution time is not the only concerns. We have to consider power consumption, floor space consumption for hardware and most importantly cost and budget of hardware as well.