CUDA is a parallel computing platform and programming model developed by Nvidia for general computing on its own GPUs (graphics processing units). CUDA enables developers to speed up compute-intensive applications by harnessing the power of GPUs for the parallelizable part of the computation.
While there have been other proposed APIs for GPUs, such as OpenCL, and there are competitive GPUs from other companies, such as AMD, the combination of CUDA and Nvidia GPUs dominates several application areas, including deep learning, and is a foundation for some of the fastest computers in the world.
Overview of CUDA
GPUs are hundreds/thousands of cores which are specialized for data parallel processing. This makes extremely fast and highly parallel workloads such as Deep learning, Image processing and linear algebra.
Data Parallelism : It means data is spread across many cores with each core doing a same operation on a small piece of data. In CUDA this model is called SIMT : Single Instruction, Multiple Thread. It works well for larger array or matrix operations where each result element can be computed separately .
And This is where CUDA comes in…
Programming GPUs used to be a pretty difficult task, even though the hardware is flexible.
So to solve this problem NVIDIA created CUDA, which is a framework for programming NVIDIA GPUs.
-
It gives us a general purpose programming model, that is suitable for all kinds of parallel processing not just for graphics.
-
CUDA programming can be easily scaled to use the resources of any GPU that you run them on.
-
The CUDA language is an extension of C/C++ so it’s fairly easy for an C++ programmers to learn (we can also use CUDA with C or FORTRAN)
CUDA : Compute Unified Device Architecture
-
It is an extension of the C programming language.
-
An API Model for parallel computing created by NVIDIA.
-
Programs written using CUDA harness the power of GPU, thus increasing the computing power.
CUDA is a parallel computing and an API model using CUDA, one can utilize the power of NVIDIA GPUs to perform general tasks, such as multiplying matrices and performing other linear algebra operations, instead of just doing graphical calculations.
CUDA programming model is a heterogeneous model in which both the CPU and GPU are used.
In CUDA,
Host : The CPU and its memory. Device : The GPU and its memory.
Code run on the host can manage memory on both the host and device and also launches kernels which are functions executed on the device.
These kernels are executed by many GPU threads in parallel.
A typical sequence of operations for a CUDA C program is,
-
Declare and allocate host and device memory.
-
Initialize host data.
-
Transfer data from the host to device.
-
Execute one or more kernels.
-
Transfer results from the device to the host.
Difference between CUDA and openCL:
-
CUDA is a proprietary framework created by NVIDIA.
And openCL (Open Compute Language) is an open standard that runs on hardware by multiple vendors including desktops or laptops GPUs by AMD/ATI and NVIDIA (not much efficient as CUDA).
-
CUDA accelerates more features and provides better acceleration.
-
Using openCL, migrating to other platforms is easy.
Using CUDA, it's harder to migrate because it has explicit optimization options to harness more GFLOPs percentage per architecture.
-
CUDA is better for solving large and sparse linear systems furthermore, it is possible to note that openCL, despite being an open standard may be considered more complex than CUDA in relation to programming.
CUDA has been developed specially for NVIDIA’s GPU, hence CUDA can’t be programmed on AMD GPUs.AMD GPUs won’t be able to run the CUDA binary (.cubin) files as these files are specially created for the NVIDIA GPU architecture.But openCL is not as much as efficient as CUDA in NVIDIA.
The CUDA Toolkit
To use CUDA we have to install the CUDA toolkit, which gives us a bunch of different tools.
NVCC Compiler : (NVIDIA CUDA Compiler) which processes a single source file and translates it into both code that runs on a CPU known as Host in CUDA, and code for GPU which is known as a device.
Debugger : The toolkit includes the debugging tool. CUDA GDB - The NVIDIA tool for debugging CUDA applications running on Linux and Mac, providing developers with a mechanism for debugging CUDA applications running on actual hardware. CUDA-GDB is an extension to the x86-64 port of GDB, the GNU Project debugger.
NVIDIA Visual Profiler : The NVIDIA Visual Profiler is a cross-platform performance profiling tool that delivers developers vital feedback for optimizing CUDA C/C++ applications.First introduced in 2008, Visual Profiler supports all 350 million+ CUDA capable NVIDIA GPUs shipped since 2006 on Linux, Mac OS X, and Windows. The NVIDIA Visual Profiler is available as part of the CUDA Toolkit.
Documentation : There are a bunch of sample programs and user guides.
Libraries : There are libraries for various domains such as Math Libraries (cuBLAS, cuFFT, cuRAND, cuSOLVER, cuTENSOR etc.) , Parallel Algorithm Libraries (nvGRAPH, Thrust), Deep Learning Libraries (cuDNN, TensorRT, deepStream SDK), Image and Video Processing Libraries (nvJPEG, NVIDIA Codec SDK), Communication Libraries (NCCL) etc.
Programming with CUDA
Programming model and how that model maps to hardware?
How to Launch kernels, debugging device code and handling errors?
The CUDA Programming Model
You will learn the software and hardware architecture of CUDA and they are connected to each other to allow us to write scalable programs.
-
Software : Drivers and Runtime API.
-
Execution Model : Kernels, Threads and Blocks.
-
Hardware Architecture : Which provides faster and scalable execution of CUDA programs.
Software
-
Driver API : The CUDA display driver includes a low level interface called the driver API. This is available in any systems with NVIDIA Driver.
-
Runtime API : The CUDA toolkit includes the higher level interface called the Runtime API. We can access it by using the CUDA syntax extensions and compiling your program with NVCC.
#include<cuda_runtime_api.h>
This provides all the basic functions we use like cudaMalloc(), cudaMemcpy() etc.
We can find the API version with deviceQuery sample.
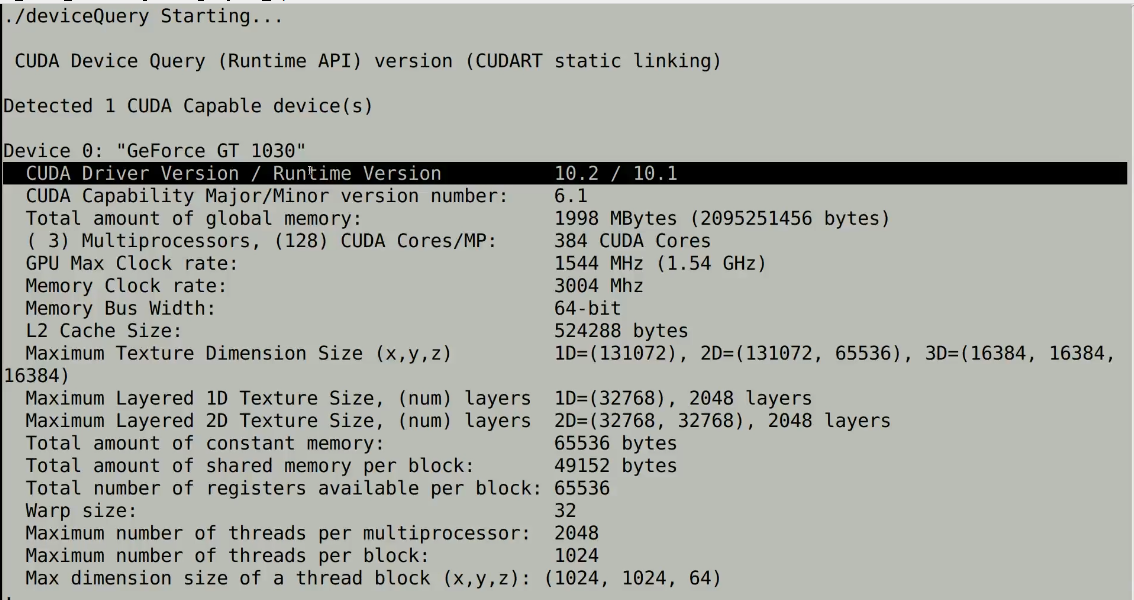
Execution Model
- Kernel : A kernel is a special function to be run on a GPU (device) instead of a CPU (host). We use the keyword __global__ to define a kernel.
Kernels are launched in the host and then executed in parallel by multiple threads on the device.
Kernels are the parallel programs to be run on the device (the NVIDIA graphics card inside the host system).
Typically one thread for each data element you want to process.
-
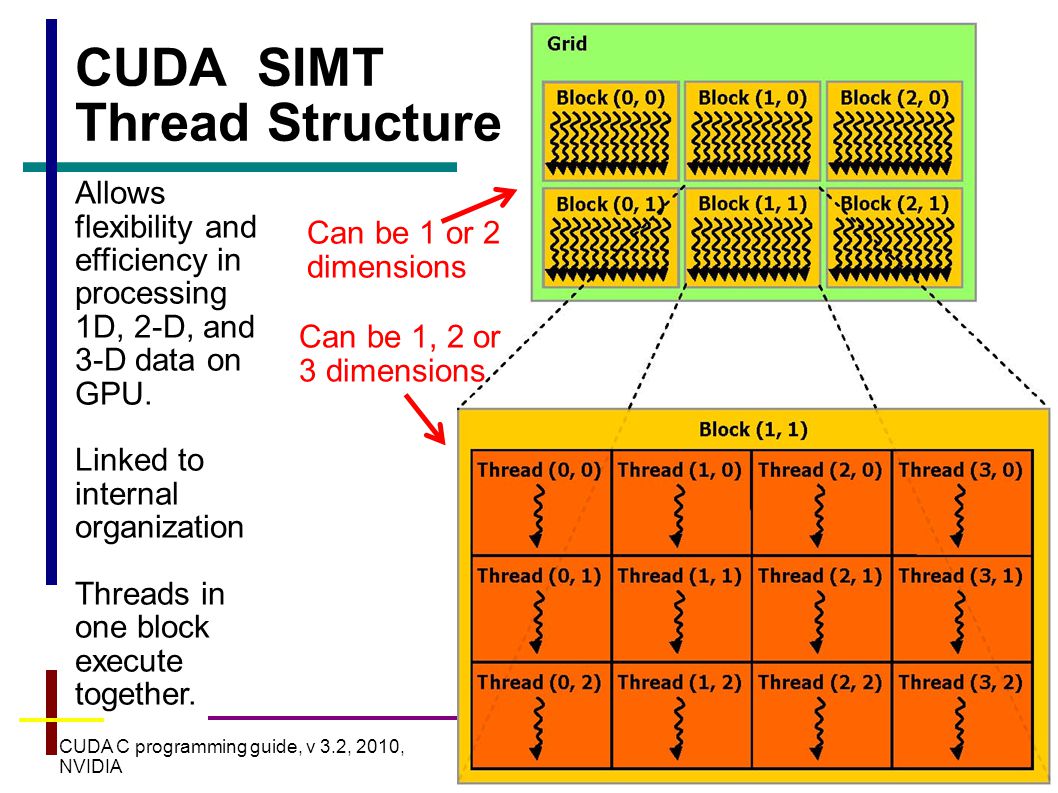
Threads and Blocks :
-
Threads are grouped into the blocks and the blocks are arranged into a grid.
-
Blocks and Grid can have 1, 2 & 3 dimensions.
-
Threads within the same block share certain resources and can communicate or synchronize with each other.
-
This is very important when we start implementing some more complicated parallel algorithms.
-
The arrangement of the grid can also impact the performance.
Hardware Architecture
CUDA devices contain multiple streaming multiprocessors (SMs). This uses Single Instructions Multiple Thread (SIMT) architecture with hardware multithreading support.
-
Streaming Multiprocessors (SMs)
-
SIMT Architecture
-
Hardware Multithreading
Streaming Multiprocessors (SMs)
A CUDA device is made up with several streaming multiprocessors or SMs.
Each SMs contains a number of CUDA cores as well as some shared cache, Registers and memory which all are shared between the cores.
The device also has a larger pool of global memory which is shared between the SMs.
The exact no. depends on your hardware.
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1080" CUDA
Driver Version / Runtime Version 10.0 / 10.0 CUDA
Capability Major/Minor version number: 6.1
Total amount of global memory: 8119 MBytes (8513585152 bytes)
Compute Capability
(Version No. which identifies general specifications of a CUDA device.)
Every CUDA device is identified by a compute capability, which indicates its general Hardware features and specifications.
Appendix H - Compute Capabilities
SIMT Architecture
NVIDIA called their hardware architecture SIMT for Single Instruction Multiple Thread.
This basically means that you have many light weight threads running the same instructions across different data.
In SIMT architecture you can adjust the no. of threads. In each thread actually it has some independent states.
Individual threads can even run different instructions although are typically less efficient.
This architecture allows CUDA programs to scale across different hardware. You don't need to worry about the exact number of SMs or cores available, because CUDA will take care of creating and scheduling all your threads.
Warps
CUDA hardware executes threads in groups of 32 which are called warps. All the thread in the warps run at the same time on the same SM and typically will execute the same instructions.
Hardware Multithreading
This hardware multithreading model allows CUDA to manage thousands of threads very efficiently.
So putting this all together,
This is basically what happens when you run a kernel.
Running a Kernel :
- The blocks are assigned to available SMs.
You are often having more blocks that run one time in which case some of them are in wait.
-
Each block is split into warps of 32 threads, which are scheduled and run on the SMs.
-
You can have multiple warps/blocks running on each SM and the hardware will switch between then whenever a warp needs to wait.
-
As blocks finish executing, the SMs are freed up and CUDA will schedule new blocks until the entire grid is done.
A Basic CUDA (compute unified device architecture) Program Outline
Host The CPU and its memory (host memory)
Device The GPU and its memory (device memory)
int main(){
// Allocate memory for array on host (CPU)
// Allocate memory for array on device
// Fill array on host
// Copy data from host array to device array
// Do something on device (e.g. vector addition)
// Copy data from device array to host array
// Check data for correctness
// Free Host Memory
// Free Device Memory
}
Let’s Come to the code::
The vector addition sample adds two vectors A and B to produce C, where Ci = Ai + Bi.
Basically this is the CUDA kernel.
//Each thread takes care of one element of c
__global__ void vecAdd(double *a, double *b, double *c, int n)
{
// Get our global thread ID
int id = blockIdx.x*blockDim.x+threadIdx.x;
// Make sure we do not go out of bounds
if (id < n)
c[id] = a[id] + b[id];
}
__global__ : Indicates the function is a CUDA kernel function – called by the host and executed on the device.
__void__ : Kernel does not return anything.
int *a, int *b, int *c : Kernel function arguments ( a, b, c are pointers to device memory)
**int i = blockDim.x * blockIdx.x + threadIdx.x; ** This defines a unique thread id among all threads in a grid.
blockDim : Gives the number of threads within each block
blockIdx : Specifies which block the thread belongs to (within the grid of blocks)
threadIdx : Specifies a local thread id within a thread block


int main( int argc, char* argv[] )
{
// Size of vectors
int n = 100000;
Allocate memory for array on host
// Host input vectors
double *h_a;
double *h_b;
//Host output vector
double *h_c;
Allocate memory for array on device(GPU)
// Device input vectors
double *d_a;
double *d_b;
//Device output vector
double *d_c;
// Size, in bytes, of each vector
size_t bytes = n*sizeof(double);
Simple CUDA API for handling device memory cudaMalloc(), cudaFree(), cudaMemcpy()
// Allocate memory for each vector on host
h_a = (double*)malloc(bytes);
h_b = (double*)malloc(bytes);
h_c = (double*)malloc(bytes);
// Allocate memory for each vector on GPU
cudaMalloc(&d_a, bytes);
cudaMalloc(&d_b, bytes);
cudaMalloc(&d_c, bytes);
int i;
// Initialize vectors on host
for( i = 0; i < n; i++ ) {
h_a[i] = sin(i)*sin(i);
h_b[i] = cos(i)*cos(i);
}
cudaMemcpy() copies elements b/w host and device
// Copy host vectors to device
cudaMemcpy( d_a, h_a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy( d_b, h_b, bytes, cudaMemcpyHostToDevice);
Thread Block organization
int blockSize, gridSize;
// Number of threads in each thread block
blockSize = 1024;
// Number of thread blocks in grid
gridSize = (int)ceil((float)n/blockSize);
Execute the kernel
vecAdd<<<gridSize, blockSize>>>(d_a, d_b, d_c, n);
Copy array back to host
cudaMemcpy( h_c, d_c, bytes, cudaMemcpyDeviceToHost );
Sum up vector c and print result
double sum = 0;
for(i=0; i<n; i++)
sum += h_c[i];
printf("final result: %f\n", sum/n);
Release device memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
Release host memory
free(h_a);
free(h_b);
free(h_c);
return 0;
}
This was basic vector addition program in CUDA.
Kernel Execution Configuration
Kernel execution configuration is to control the layout of threads and blocks when running a kernel.
Launching kernel:
my_kernel«< GRID_DIMENSION, BLOCK DIMENSION »>(…)
Triple bracket syntax used for launching the kernels.
The first argument is the grid dimension, which defines the number and layout of the blocks and the second argument is block dimension. These values can be integer for dimensional grid.
Code:
// Demonstration of kernel execution configuration for a 1D-Grid
#include <cuda_runtime_api.h>
#include <stdio.h>
// Error checking macro
#definecudaCheckError(code){
if ((code) != cudaSuccess) {
fprintf(stderr, "Cuda failure %s:%d: '%s' \n", __FILE__, __LINE__,
cudaGetErrorString(code));
}}
__global__ void kernel_1d(){
int index = blockIdx.x * blockDim.x + threadIdx.x;
printf("block %d, thread %d, index %d\n", blockIdx.x, threadIdx.x, index);
}
int main(){
kernel_1d<<<4, 8>>>();
cudaCheckError(cudaDeviceSynchronize());
}
Result :
block 3, thread 0, index 24
block 3, thread 1, index 25
block 3, thread 2, index 26
block 3, thread 3, index 27
block 3, thread 4, index 28
block 3, thread 5, index 29
block 3, thread 6, index 30
block 3, thread 7, index 31
block 0, thread 0, index 0
block 0, thread 1, index 1
block 0, thread 2, index 2
block 0, thread 3, index 3
block 0, thread 4, index 4
block 0, thread 5, index 5
block 0, thread 6, index 6
block 0, thread 7, index 7
block 1, thread 0, index 8
block 1, thread 1, index 9
block 1, thread 2, index 10
block 1, thread 3, index 11
block 1, thread 4, index 12
block 1, thread 5, index 13
block 1, thread 6, index 14
block 1, thread 7, index 15
block 2, thread 0, index 16
block 2, thread 1, index 17
block 2, thread 2, index 18
block 2, thread 3, index 19
block 2, thread 4, index 20
block 2, thread 5, index 21
block 2, thread 6, index 22
block 2, thread 7, index 23
We are calling printf function in device code. The cuda runtime does a magic behind the scenes here, so the messages we print here, were actually copied back to the host and displayed just like a regular printf.
It's pretty useful for testing and debugging.
Now we’ll launch this kernel with 4 blocks, each containing 8 threads for a total of 32.
One thing you will notice here is that the result of this code is out of order. The print statements from each block are grouped together because the block fits into a single warp so it all runs at once.
But the blocks run in parallel across multiple SM so they can run in any order.
Here is the code which calculates that-
int index = blockIdx.x *blockDim.x + threadIdx.x;
It uses the block no., the block size and the thread index within the block to determine overall index into our data.
For 2D data : Image or Matrix or 3D dim3 is there. We’ll look into that later blogs.
Choosing Block Size :
-
Performance is depending on Block size. Block size will have a big impact.
-
Occupancy - Keeping all SMs busy.
-
Synchronization and Communication (between threads and blocks)
Occupancy :
This comes up alot when talking about CUDA performance.
Occupancy means the ratio between the no. of active warps and the maximum number of devices can support.
In general “Higher is better” as it allows the scheduler to see memory access.
Code:
// Demonstration of the CUDA occupancy API.
#include <cuda_runtime_api.h>
#include <stdio.h>
__global__ void kernel_1d() {}
int main()
{
// The launch configurator returned block size
int block_size;
// The minimum grid size needed to achieve max occupancy
int min_grid_size;
cudaOccupancyMaxPotentialBlockSize(&min_grid_size, &block_size, kernel_1d, 0, 0);
printf("Block size %d\nMin grid size %d\n", block_size, min_grid_size);
}
Result :
Block size 1024
Min grid size 26
Occupancy API telles us Best block size is 1024 and to maximize occupancy we need 26 blocks. We can use this info to calculate the grid layer for my kernel.
Basics of debugging with CUDA - GDB on linux and handling errors
CUDA - GDB is the extension of GDB debugger, which supports CUDA debugging.
It supports breakpoints, single stepping and everything else you expect from a debugger.
Debug the Host and Device code-
nvcc -g -G -o test_bug test_bug.cu
-G enables debugging for device code.
-g enabling debug symbols as in GCC.
References :